This is a second part of our series about building your own data center. It picks up where we left off last time as we look at choosing the right hardware, ensuring high availability of all parts of the infrastructure and connecting all of the components into a modern computer network.


Last time we focused on choosing the right location for the data center and talked about basic power supply and cooling considerations, physical security and dual connectivity. We’re on the right track, but there’s still a long way to go till we reach a working infrastructure. Let’s go.
When building a cloud, network is key
Today’s apps demand a lot from network technologies and this makes the development move quickly forward. In the past, the preferred network architecture similar to a tree – made of three parts, access, aggregation and core – is today considered too burdensome and not effective. One of the main arguments against this topology is the adoption of the Spanning Tree Protocol – or STP – that prevents bridge loops. Bridge loops are undesirable in networks and STP prevents them by switching off the redundant pathways. This means that only a part of the total throughput of the network is actually used. The redundant lines are activated only when the primary pathway disconnects.
The newer leaf-spine design both aggregation and access layers of the three-layer architecture. Instead, it uses a network of backbone (spine) and endpoint (leaf) switches in a full-mesh topology. This way, every spine switch is directly connected to all leaf switches and all the lines are active at the same time. This design allows for higher total throughput and lower latency than the first architecture at the same cost. The undesirable STP can be replaced with L3 protocols or modern L2 protocols like Trill.
Should you choose a three-layer or a leaf-spine architecture?
For most data centers and applications, the traditional three-layer approach is entirely sufficient. However, the trend to shift away from STP and L2 generally is difficult to ignore and network hardware manufacturers themselves will probably try to push customers towards leaf-spine architectures. And the benefits of the new topology are plain to see when using some modern apps that require a high throughput of data.
With that in mind, the recommendation today is to go with the leaf-spine architecture, even though specifics of implementations by various vendors can differ. Though the gold standard still applies – every important component is doubled in the system, so that a failure of any part of the network infrastructure won’t make the endpoint inaccessible.
You cannot move forward without servers
Although the growth in performance available to servers was huge over the last few years, it’s this segment of the data center industry that is usually the most conservative. Servers come in different shapes and sizes, usually tower, rack or blade. Tower and rack formats are full-fledged standalone servers.
Blade servers on the other hand need a special chassis that provides power, cooling, connectivity and management shared to all – usually sixteen – of the blade servers inside. The thinking behind this approach is to increase the density of servers in the data center and lower the needs for space. And the chassis providing shared power is usually somewhat more energy efficient than regular servers.
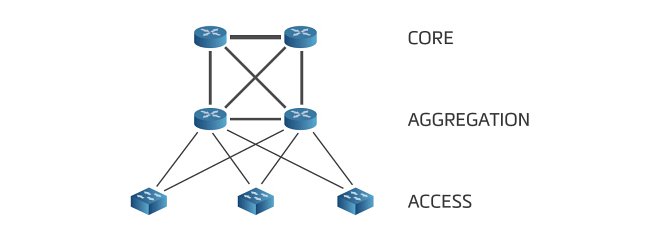
The traditional three-layer architecture is the most common multi-layer architecture out there.
A simple rule to follow is this: a blade chassis is best bought already full. So if you decide to build your application on blade servers and scale up as the number of your users grow, the unit of your growth probably won’t be a server, but a whole full chassis.
Another aspect to consider is increasing of the so-called failure domain. This important term is used when defining redundancy and describes the group of services that would be affected by a failure of a specific component. When working with blade servers, the whole chassis could theoretically fail, so to obtain the typical N+1 redundancy, we now need another full chassis. But that is a significant expense over one more rack or tower server. That’s why generally blade servers are best used in higher quantities, where their advantages of cheaper maintenance and easier management work best.
New trends defy the old classification
Hardware manufacturers realise that for most of their customers the blade chassis is just too big and expensive. That’s why they try to combine the best of the both worlds and create high-density servers with effective power supplies and small failure domain. These come in forms of small chassis for two to eight servers with shared power and management. It’s an interesting trend that could make blade servers work in the Czech market as well.
When designing a data center, if at all possible, you should already know what servers it’s going to use. Higher server density means a higher concentration of waste heat and a need for a more powerful cooling solution.
There are some pitfalls. Here’s what you should avoid
It’s possible to find so-called “servers” made from regular desktop components. On the first glance this results in a powerful machine for low price. However, it’s usually best to avoid these. Money saved on the initial purchase gets spent later on maintenance, because these servers don’t have out-of-band management and even routine problems like “stuck firewall” need to be solved by going to the data center directly.
I also advise you to avoid desktop hard drives and power supply units, as these are the most fault-prone components of computers today. These shortcomings get magnified in data centers. The same can be said about desktop solid state drives or SSDs – their performance radically drops when the disk has been filled once. This phenomenon known as “write-cliff” happens because of a garbage-collection process that is making space for new writes. It can be quite difficult to spot in on a regular desktop pc, but on a database server it can wreak annoying and difficult-to-diagnose problems. Manufacturers work around this by giving their SSDs higher capacity than they actually report to the system. The remaining capacity is used to mitigate the write cliff effect and to protect data when the drive nears its end-of-life.
Now to the “data” part of a data center. The question of storage
The term storage used in a data center context generally means “a method for storing data”. This can be achieved by a local disk right in the data center, or through a complex structure of disk arrays.
DAS: Direct Attached Storage – The workhorse of data centers
The basic level of storage where all the drives are connected directly to a server. To make this storage available over the network, the hosting server must use a special software that makes the data available. The clients then connect to the host server. If the host server fails, data is inaccessible.
NAS: Network Attached Storage – It’s improving quickly
The NAS is a storage space connected to the network with file-level access. It was developed as an answer to a call for a specialized device of this type. It allows simultaneous access to several clients and in the past was used as a cheap and easy way to share data over a network. Today, there are NAS devices so fast, reliable and sophisticated so that they’re on a similar level as a SAN solution.
SAN: Storage Area Network – Fast, reliable and expensive
A high-speed network reserved for data transfer between servers and block storage (drive arrays) is called a storage area network or SAN. The most common SAN protocols are iSCSI and Fibre Channel. Both are used for a fast and reliable block data transfer. These SAN networks are usually very reliable and provide very high performance, but they are also the most expensive and difficult to prepare.
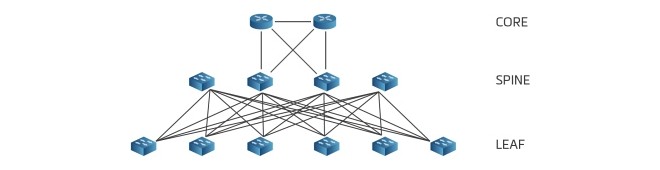
The newer leaf-spine architecture removes both aggregation and access layers. Instead it’s built around a network of backbone (spine) and endpoint (leaf) switches.
One data center might often employ all three storage approaches mentioned, however the most common in regular servers is still DAS. The fastest growing type of storage is SAN, mainly because of virtualization.
The type of storage used is always decided by the specific application. For example, a database server should be serviced by fast local drives and the high availability will be ensured on an application level, either by building a database cluster or through a simple replication. Virtualization, on the other hand, can benefit from the separation of storage and computing servers, that’s why in a data center there is usually SAN or NAS as well.
The traditional approach to SAN is still useful
The basic building block of a typical SAN is a disk array. These are specialized devices only used for a fast block access to data. A disk array usually consists of a pair of redundant controllers and one or more disk shelves. The controllers allow network access to data and work as a control element for the whole array. The disk shelves themselves are simple devices with no internal logic that just serve the purpose as a physical storage for data.
If its performance or capacity is ever not sufficient, it can be easily solved by buying other shelves full of drives. The controllers however are difficult to scale and often necessitate an upgrade to a higher level of disk array.
Alternative storage is available on commodity servers
The relatively high cost of building a SAN and problems with scaling of the controllers make way for alternative solutions. Thanks to a low price of regular servers, rising computational power and higher storage density, it’s now becoming practical to build a modern SAN out of regular servers. There are many solutions like this in the market, even made by well-known brands. When designing a network infrastructure like this, it is important to consider the huge network traffic between individual storage servers and prepare everything accordingly.
After reading this article, you should be well-versed in both traditional and modern technologies that are used in today’s data centers. The next and final article of this series will help you move your company’s apps into the data center and make them run smoothly in the cloud.
The article was previously published in the professional journal IT Systems, issue 11/2014